AlphaZero способна научить себя играть в игры на самых высоких уровнях
AlphaZero, представляет собой систему обучения с подкреплением, которая, как следует из названия, означает, что она учится, многократно играя в игру и учась на своем опыте.

Команда исследователей из группы DeepMind и Университетского колледжа в Великобритании разработала систему искусственного интеллекта, способную научить себя играть и осваивать три сложные настольные игры. В своей статье, опубликованной в журнале Science, группа описывает свою новую систему и объясняет, почему они считают, что она представляет собой еще один большой шаг вперед в развитии систем ИИ.
Мюррей Кэмпбелл из Исследовательского центра им. Т. Дж. Уотсона в США предлагает статью о работе, проделанной командой в том же выпуске журнала.
Прошло более 20 лет с тех пор, как суперкомпьютер, известный как Deep Blue, победил чемпиона мира по шахматам Гари Каспарова, показывая миру, как далеко продвинулись ИИ вычисления. С тех пор компьютеры становились все умнее и теперь побеждают людей в таких играх, как шахматы, сёги и го.
Но такие системы были настроены, чтобы сделать их действительно хорошими в одной игре. В своей новой работе исследователи создали систему искусственного интеллекта, которая не только хороша в более чем одной игре, но и приобретает опыт игры самостоятельно.
Новая система, получившая название AlphaZero, представляет собой систему обучения с подкреплением, которая, как следует из названия, означает, что она учится, многократно играя в игру и учась на своем опыте. Это, конечно, очень похоже на то, как учатся люди.

Credit: DeepMind Technologies Ltd
В начале изложен базовый набор правил, после чего компьютер начинает играть сам с собой. Не нужно даже играть с другими партнерами. Он играет сам с собой множество раз, отмечая, какие игры включают в себя хорошие ходы и, следовательно, выигрыши, а какие — плохие ходы и проигрыши. Со временем все это улучшается.
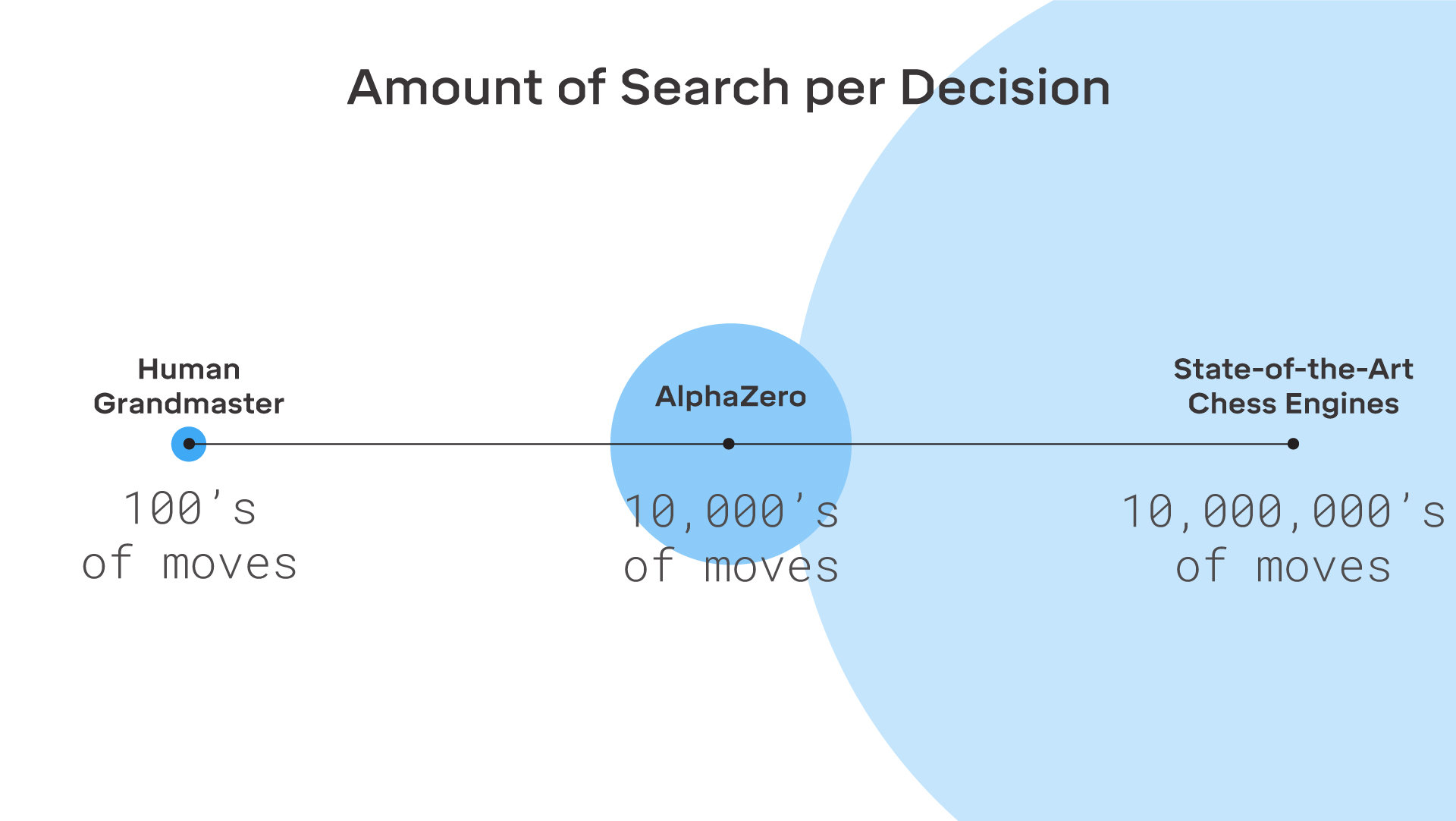
В конце концов, AlphaZero становится настолько хорош, что может побеждать не только людей, но и другие специализированные системы ИИ для настольных игр. Система также использовала метод поиска, известный как поиск по методу Монте-Карло. Сочетание двух технологий позволяет системе научиться лучше играть в игры. Исследователи также наделили свою тестовую систему мощью, применив 5000 процессоров, что ставит ее в один ряд с большими суперкомпьютерами.
DeepMind Technologies Ltd
В шахматах AlphaZero впервые выиграл у Stockfish (рейтинг ЭЛО ~3500) всего через 4 часа тренировки; в сёги AlphaZero впервые опередил Elmo через 2 часа; а в Go AlphaZero впервые превзошла версию AlphaGo, которая победила легендарного игрока Ли Седоля в 2016 году после 30 часов.
Обновленная AlphaZero разгромила Stockfish 8 в новом матче из 1,000 партий со счетом +155 -6 =839.
AlphaZero также победила Stockfish в серии матчей с дачей форы по времени. Она выигрывала у обычной компьютерной программы, даже оставив себе в десять раз меньше времени на обдумывание.
В дополнительных матчах новая AlphaZero победила «последнюю разрабатываемую версию» Stockfish почти с тем же результатом, что и в матче со Stockfish 8. В окончательной версии статьи указано, что AlphaZero играла против последней разрабатываемой версии Stockfish на 13 января 2018, то есть, Stockfish 9.

Источник: DeepMind и Science.
Машинно обучаемая программа также выиграла все матчи у «варианта Stockfish, который, по сообщению DeepMind, использует сильную дебютную книгу». Дебютная книга помогла Stockfish, наконец, выиграть довольно много партий белыми—но этого было недостаточно, чтобы выиграть матч.
Отчет будет опубликован в статье издания Science, но он заранее был предоставлен избранным шахматным СМИ разработчиками из DeepMind, компании, работающей в Лондоне и принадлежащей Alphabet, холдингу, который владеет и Google.
Матч из 1,000 партий проводился в начале 2018 года. AlphaZero и Stockfish давалось по три часа на партию каждой с добавлением 15 секунд на ход. Выбранный контроль времени позволил отбросить в сторону один из самых веских доводов против значимости прошлогоднего матча: якобы, контроль времени по минуте на ход, применявшийся в 2017 году, был невыгоден для Stockfish.
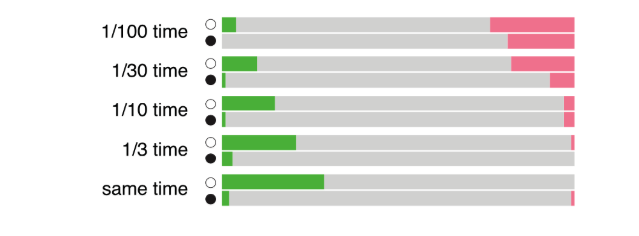
Три часа на партию с добавлением 15 секунд не оставляют места для подобных споров. Это количество времени огромно для любого компьютерного движка. В партиях с форой по времени AlphaZero доминировала даже при соотношении времени 10-1. Stockfish добился преимущества в счете, только получив в 30 раз больше времени на обдумывание.
Результаты AlphaZero в партиях с форой по времени свидетельствуют о том, что она не только играет намного сильнее любой традиционной шахматной программы, но и также ищет ходы намного более эффективным образом. По сообщению DeepMind, AlphaZero использует поиск по дереву Монте-Карло, изучая около 60,000 позиций в секунду в сравнении с 60 миллионами, которые оценивает Stockfish.
The full peer-reviewed @sciencemagazine evaluation of #AlphaZero is here — a single algorithm that creatively masters chess, shogi and Go through self-play https://t.co/E3OPUOIFw4 pic.twitter.com/rEeuEseEil
— Google DeepMind (@GoogleDeepMind) December 6, 2018
До сих пор AlphaZero освоил шахматы, сёги и го — игры, которые особенно хорошо подходят для приложений ИИ. Кэмпбелл предполагает, что следующим шагом для ИИ-систем может стать переход на такие игры, как покер или даже популярные видеоигры, вроде Dota 2.
«Полученные результаты приближают нас еще на один шаг к выполнению долгосрочной задачи разработчиков искусственного интеллекта: созданию обобщенного игрового интеллекта, который может освоить любую игру», — говорят исследователи из DeepMind.