GPT-4 становится на 30% точнее, когда его просят критиковать собственную работу

Похоже, что искусственный интеллект GPT-4 может сделать огромный скачок вперед, если он просто внимательно присмотрится к себе. Исследователи попросили GPT подвергнуть критике свою собственную работу, что повысило его производительность на 30%.
«Не каждый день люди разрабатывают новые методы для достижения самых современных стандартов, используя процессы принятия решений, которые когда-то считались уникальными для человеческого интеллекта», — пишут исследователи Ноа Шинн и Ашвин Гопинат. «Но это именно то, что мы сделали».
Техника «Reflexion» использует и без того впечатляющую способность GPT-4 выполнять различные тесты и представляет «структуру, которая позволяет агентам ИИ эмулировать человеческое саморефлексию и оценивать ее производительность».
По сути, она вводит дополнительные шаги, на которых GPT-4 разрабатывает тесты для критики своих собственных ответов, ищет ошибки и оплошности, а затем переписывает свои решения на основе того, что он нашел.
Ученые использовали эту технику для нескольких различных тестов производительности.
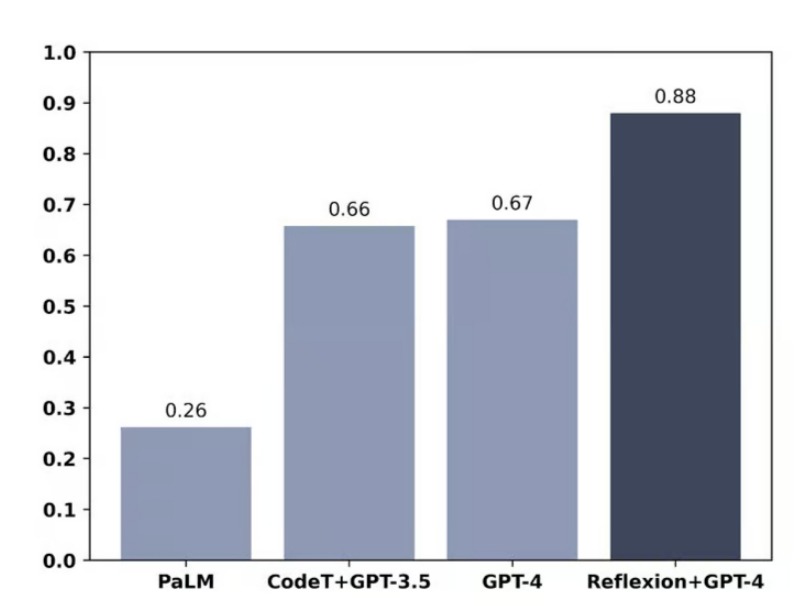
В тесте HumanEval, который состоит из 164 задач программирования на Python, с которыми модель никогда не сталкивалась, GPT-4 набрал рекордные 67%, но с использованием техники Reflexion его результат подскочил до очень впечатляющих 88%.
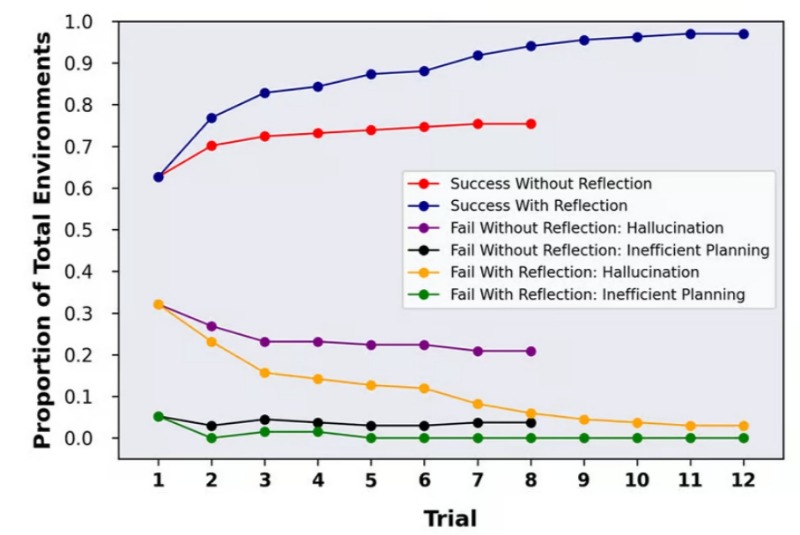
В тесте Alfworld, который проверяет способность ИИ принимать решения и решать многоэтапные задачи, выполняя несколько различных допустимых действий в различных интерактивных средах, техника Reflexion повысила производительность GPT-4 примерно с 73% до почти идеальных 97%, не выполнив только 4 из 134 задач.
В другом тесте под названием HotPotQA, GPT-4 был предоставлен доступ к Википедии, а затем предоставлено 100 из возможных 13 000 пар вопросов/ответов, которые «заставляют агентов анализировать содержание и аргументы в нескольких подтверждающих документах».
В этом тесте GPT-4 показал точность всего 34%, но GPT-4 с Reflexion показал значительно лучшие результаты с 54%.
Все чаще и чаще решение проблем ИИ оказывается зависимым в большей степени от самого ИИ.
В некотором смысле это немного похоже на генеративно-состязательную сеть, в которой два ИИ оттачивают навыки друг друга, один пытается генерировать изображения, например, которые нельзя отличить от «настоящих» изображений, а другой пытается отличить поддельные от настоящих.
Но в данном случае GPT является и автором, и редактором, работающим над улучшением собственного продукта.
Присоединяйтесь к нам в соцсетях
